High Performance Embedded Systems
- Imprimer
- Partager
- Partager sur Facebook
- Partager sur LinkedIn
Équipe action
L'équipe-action HPES (High Performance Embedded Systems) est un projet financé par le LabEx PERSYVAL.
Description scientifique
Le domaine de l'informatique a récemment été profondément modifié par l'émergence de ce que l'on appelle les processeurs multicœurs. Au sein d'une même puce, plusieurs unités de calcul sont mises en œuvre. Ce concept architectural permet de répondre aux exigences de performance tout en respectant des contraintes strictes en matière de consommation d'énergie. Les processeurs multicœurs sont utilisés pour les ordinateurs portables, les processeurs graphiques (GPU), les plates-formes de calcul à haute performance (HPC), mais aussi pour les systèmes embarqués tels que les téléphones mobiles. De plus, les multicœurs haute performance à faible consommation développés pour les systèmes embarqués seront bientôt utilisés dans les centres de données pour le calcul de haute performance. Cela pose de nouveaux défis scientifiques aux concepteurs d'architectures, de systèmes et d'applications qui sont confrontés à des plates-formes de calcul massivement parallèles.
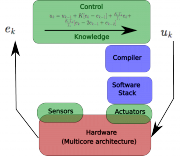
Le nombre de cœurs sur une puce augmente rapidement. Dans le même temps, la bande passante de la mémoire augmente trop lentement pour garantir les performances que ces plates-formes multicœurs devraient atteindre. Ce phénomène est connu sous le nom de "mur de la mémoire" et il n'existe actuellement aucune solution efficace pour dépasser cette limite. Avec l'augmentation du nombre de cœurs, la cohérence de la mémoire cache devient également un énorme défi.
La consommation d'énergie est également un défi de taille car elle impose de fortes contraintes à la plateforme informatique, quel que soit le domaine d'application. La première machine classée dans le Green500 a un ratio de performance énergétique de 2 Gflops par watt. Ce ratio doit être amélioré de 30 fois si l'on considère l'informatique exascale. Le processeur multicœur peut contribuer à l'amélioration de ce ratio, mais la pile logicielle doit également évoluer pour favoriser cette amélioration.
Membres
- H-P. Charles (CEA-LIST)
- L. Fesquet (TIMA)
- S. Lesecq (CEA-LETI)
- S. Mancini (TIMA)
- N. Marchand (Gipsa)
- J-F. Méhaut (LIG)
- F. Rastello (INRIA)
- E. Rutten (INRIA)
- L. Vincent (post-doc)
- Naweiluo Zhou (doctorant)
Séminaires internes
- 18/10/2013 : Control for MPSoC architecture
- 28/11/2013 : Dynamic compilation for everyone
- 27/01/2014 : Hardware NDAP cache for arrays prefetchs
- 01/04/2014 : Improving the performance of transactional memory applications on multicore
- Augmenting the Roofline Model via Lower Bound on Data Movement
Évènements "Journées de la compilation"
- 12/11/2014 : Journée compilation, soutenance de Victor Lomüller
- 18/09/2015 : Journée compilation, soutenance de Fernando Endo
- 01/10/2015 : Journée compilation (à Saclay), soutenance de Alexandre Aminot
- 13-14/12/2016 : Journée compilation, soutenance de Diogo Sampaio
- 17-23/10/2017 : 3rd Grenoble Workshop on Autonomic Computing and Control
Publications
2016
Autonomic Parallelism and Thread Mapping Control on Software Transactional Memory Naweiluo Zhou, Gwenaël Delaval, Bogdan Robu, Eric Rutten, Jean-François Méhaut 13th IEEE International Conference on Autonomic Computing (ICAC 2016), Jul 2016, Würzbourg, Germany. https://hal.archives-ouvertes.fr/hal-01309681
Control of Autonomic Parallelism Adaptation on Software Transactional Memory Naweiluo Zhou, Gwenaël Delaval, Bogdan Robu, Eric Rutten, Jean-François Méhaut 2016 International Conference on High Performance Computing & Simulation (HPCS 2016) , Jul 2016, Innsbruck, Austria. pp.180-187, 2016, https://hal.archives-ouvertes.fr/hal-01309195
Autonomic Parallelism Adaptation for Software Transactional Memory Naweiluo Zhou, Gwenaël Delaval, Bogdan Robu, Éric Rutten, Jean-François Méhaut Conférence d’informatique en Parallélisme, Architecture et Système (COMPAS), Jul 2016, Lorient, France https://hal.inria.fr/hal-01312786
Autonomic Parallelism Adaptation on Software Transactional Memory Naweiluo Zhou, Gwenaël Delaval, Bogdan Robu, Éric Rutten, Jean-François Méhaut [Research Report] RR-8887, Univ. Grenoble Alpes; INRIA Grenoble. 2016, pp.24 https://hal.inria.fr/hal-01279599v2
Autonomic Thread Parallelism and Mapping Control for Software Transactional Memory, Naweiluo Zhou Distributed, Parallel, and Cluster Computing [cs.DC]. UJF Grenoble-1; INRIA Grenoble, 2016. English https://hal.archives-ouvertes.fr/tel-01408450
2015
Chadi Al Khatib, Mohamed Gana, Chouki Aktouf, Laurent Fesquet, “A new methodology for implementing a distributed clock management system for low-power design”, HiPEAC 2015 Conference, Workshop on High Performance Embedded Systems, January 19 - 21, 2015, Amsterdam, Netherlands.
Chadi Al khatib, Claire Aupetit, Cyril Chevalier, Chouki Aktouf, Gilles Sicard, Laurent Fesquet, "A Generic Clock Controller for Low Power Systems: Experimentation on an AXI Bus", IFIP/IEEE International Conference on Very Large Scale Integration (VLSI-SoC), October 5-7, 2015, Daejeon, Korea
2014
M. Berekmeri, D. Serrano, S. Bouchenak, N. Marchand and B. Robu, "A Control Approach for Performance of Big Data Systems", Vol. 19(1), IFAC World Congress, 2014.
M. Berekmeri, D. Serrano, S. Bouchenak, N. Marchand and B. Robu, "Application du contrôle pour garantir la performance des systèmes Big Data", Conférence francophone d’informatique en parallélisme, architecture et système (ComPAS), 2014
Ngoc-Mai Nguyen, Warody Lombardi, Edith Beigné, Suzanne Lesecq, Xuan-Tu Tran, "FIFO-level-based Power Management and its Application to an H.264 Encoder", IECON’14, 40th Annual Conference of the IEEE Industrial Electronics Society, 30, October - 01, November, 2014 Dallas, TX, USA. Best presentation Awards
Soguy Mak Karé Gueye, N. de Palma, Eric Rutten, Alain Tchana, Nicolas Berthier, “Coordinating Self-Sizing ans Self-Repair Managers for Multi-Tier Systems”, Journal of Future Generation of Computer Systems (FCGS), Numéro 35, pp 14-26, 2014, Springer, IECON’14, 40th Annual Conference of the IEEE Industrial Electronics Society, 30, October - 01, November, 2014, Dallas, TX, USA. BEST Presentation Award.
Luiz Fabrício Góes, Christiane Pousa Ribeiro, Marcio Castro, Jean-François Mehaut, Murray Cole, and Marcelo Cintra. “Automatic Skleton-Driven Memory Affinity for Transactional Worklist Applications”. International Journal of Parallel Programming (IJPP), volume 42, numéro 2, pp 365-382, 2014, Springer
Stéphane Mancini “Adaptation en boucle fermée d'un préchargement stockastique dans les tableaux” Proceedings de la conférence ComPAS'2014, Session Architecture, 23-25 Avril 2014, Neuchâtel, Suisse
Sylvain Durand, Hatem Zakaria, Laurent Fesquet, Nicolas Marchand, “A Robust and Energy-Efficient DVFS Control Algorithm for GALS-ANoC MPSoC" in Advanced Technology under Process Variability Constraints”, Advances in Computer Science : an International Journal (ACSIJ), Volume 3, Issue 1, January 2014
Stéphane Mancini “Adaptation en boucle fermée d'un préchargement stockastique dans les tableaux” conférence ComPAS'2014, Session Architecture, Neuchâtel, Suisse, 23-25 Avril 2014
Yeter Akgul, Diego Puschini, Suzanne Lesecq, Pascal Benoit, Edith Beigne, Ivan Miro-Panades, Lionel Torres, “Power management through DVFS and Dynamic Body Biasing in FD-SOI circuits”, 51th DAC Conference, San-Francisco, 1-5 June 2014
Venmugil Elango and Fabrice Rastello and Louis-Noël Pouchet and J. Ramanujam and P. Sadayappan “On Characterizing the Data Movement Complexity of Computational DAGs for Parallel Execution” 26th ACM Symposium on Parallelism in Algorithms and Architectures, SPAA '14 June 23 - 25, 2014
L. Pilla, C. Pousa Ribeiro, P. Coucheney, F. Broquedis, B. Gaujal, P. Navaux, and J.-F. Mehaut. "A Topology-aware Load Balancing Algorithm for Clustered Hierarchical Multi-core Machines." Future Generation of Computing Systems (FGCS), 30(1):191--201, 2014
2013
M. Berekmeri, D. Sarrano, S. Bouchenak, N. Marchand and B. Robu, "Modelling and Control of MapReduce Systems", Conférence francophone d’informatique en parallélisme, architecture et système (ComPAS), 2013
Fauzia, Naznin and Elango, Venmugil and Ravishankar, Mahesh and Ramanujam, J. and Rastello, Fabrice and Rountev, Atanas and Pouchet, Louis-Noël and Sadayappan, P. “Beyond Reuse Distance Analysis: Dynamic Analysis for Characterization of Data Locality Potential” ACM TACO Transaction on Architecture and Code Optimization, 2013 december
- Imprimer
- Partager
- Partager sur Facebook
- Partager sur LinkedIn